
摘 要: 以互联网上招聘信息的搜索作为切入点,研究了基于主题的信息搜索技术。详细介绍了搜索系统的结构及各部分的功能和主要算法。
关键词: 信息搜索 Spider程序 招聘信息
互联网的迅猛发展带来了信息的高速膨胀。如何快速、有效、准确地搜索信息,成为人们越来越关注的问题。虽然目前存在Google这样强大的搜索引擎,但是它并不能满足用户对于信息有效、准确查询的需求。这种通用搜索引擎的搜索结果会夹杂大量与用户感兴趣主题无关的信息。
随着招聘信息需求的大量增长,出现了51job这样的专业人才招聘网站。它可以使用户精确地查询招聘信息。但是,这类网站只包括交费企业的招聘信息,因此大部分中小公司的招聘信息不能被查询到。
针对这些问题,通过自动搜索招聘网页信息来为用户提供完全的、实时的招聘信息服务是十分必要的。通过招聘信息提取平台,不仅可以省去大量的人力、物力来收集信息,而且可以保证信息的完全,同时提供强大的查询机制。本文将研究如何快速、有效、准确地获得招聘页面。提出了基于关键词的识别算法来定位招聘网页,结合招聘页面的多层结构,达到真正快速、有效、自主的信息搜索。
1 招聘信息网页搜索
招聘信息网页的搜索是从一个公司的首页开始,搜寻该站点内的所有招聘信息网页。下面将招聘信息网页简称为招聘网页。招聘信息是指具体的招聘职位、人数和要求等信息。本文假定存在一个入口页面,将其称之为公司招聘首页。该招聘主页可能不是招聘页面,因为它不包含具体的招聘信息,但是通过该页面可以链接到很多招聘页面,通过扩展这些招聘页面,可以到达公司的所有招聘页面。招聘页面的扩展是带有启发式的,即只扩展招聘页面,不扩展非招聘页面。
从公司首页开始,可以找到招聘首页。招聘首页包含很多招聘页面和非招聘页面,招聘页面又链接到其他招聘页面或非招聘页面。通过扩展这些招聘页面,可以获得所有招聘页面。
2 系统介绍
招聘网页搜索系统由4个模块组成:入口定位模块、招聘链接识别模块、招聘页面识别模块和页面搜索模块。Web招聘信息自动搜索平台总体结构如图1所示。

首先,由入口定位模块找到公司的招聘入口页面。然后页面搜索模块由入口页面出发,通过不断扩展招聘页面来获得所有的招聘页面。在扩展过程中,使用招聘页面识别模块来判别一个页面是否是招聘页面。为了减少候选页面链接数,使用招聘链接识别模块来过滤出候选的招聘页面链接。招聘链接识别模块根据中文单词表及URL识别知识来识别链接。招聘页面识别模块通过统计页面关键词词频来识别网页。下面将详细描述各个模块的具体算法。
2.1 入口定位模块
入口定位模块采用的是自主搜索算法。其原理是基于分步的思想。假设要查找美国高校计算机方面的论文,首先可以在一个大学网址中查找计算机系主页,找到后可以查找相应的教员目录,然后通过每个教员找到论文所在的页面。在搜索过程中查找的页面称为路标网页。这样的分步查找可以极大提高搜索效率,总的搜索页面个数将大量减少,而且也提高了准确度。如果应用搜索知识的自学习,将使随后的搜索更高效。由于招聘页面一般离主页距离较近(即经过很少的点击就可以到达招聘页面),所以不需要设置路标页面,只需要在不同的分步中构建关键词词表。搜索知识的表述如图2所示。
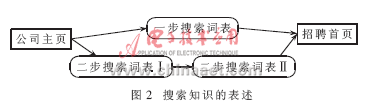
在一步搜索词表中由样本得到的有“招聘信息”、“工作机会”、“加入我们”、“招贤纳士”等关键词。在二步搜索中,第一步得到的有“关于我们”、“人力资源”、“人才中心”等关键词,第二步得到的有“工作机会”、“校园招聘”、“社会招聘”、“招聘信息”等关键词。下面是具体的处理步骤:
SearchOneSite(TermSet,SearchArea,SearchKB,EventLog,WebPageSet){
//根据搜索知识、各网链特征集以及当前搜索路径,计算各网
//链搜索优先值
1.URLSet=ComputeURLPriority(TermSet,SearchArea,
SearchKB);
//按照各网链搜索优先值将其顺序压入栈中,以便进行回溯搜索
2.PushURLSetToSearchStack(URLSet,SearchStack,SearchArea);
//从当前网链集中,弹取出一个候选URL(当前搜索优先权值
//最大)
3.OneURL=GetNextOneURL(SearchArea,SearchStack);
//若当前网链集地址已经被搜索完,则进行搜索回溯
4.If(OneURl==NULL){
if(UpdateSearchArea(SearchArea,NULL)==NOBACK)
return FALSE;
goto 3;
}
//从互联网上读取指定URL的网页判断读取是否成功
//若成功
5.If(OneWebPage==FetchOnePage(OneURL,SearchArea);
//记录当前搜索参数与结果
6.RecordEvent(OneURL,SearchArea,EventLog);
//若读取失败,则准备读取下一个网页
7.If(OneWebPage==NULL) goto 3;
//分析所获网页并取得其内容特征
8.TermSet=ParseWebPage(OneWebPage,SearchArea);
//根据当前搜索知识、网页特征与搜索路径,确定网页是否为
//下一基本网页
9.Result=CheckWebPage(TermSet,SearchArea,SearchKB);
//若是下一个网链所在网页,则更新当前搜索状态
10.If(Result==NEXTLINK)
UpdateSearchArea(SearchArea,Result);
//若是下一个基本网页,则更新当前搜索状态
11.If(Result==NEXTPAGE){
//将已搜索到的基本网页收集在一起,作为最后搜索结果
WebPageSet=WebPageSet+{OneWebPage};
//若已获最后一个基本网页,则返回搜索成功信息
if(UpdateSearchArea(SearchArea,Result)==LASTONE)return TRUE;
}
//准备回溯搜索
else goto 3;
//继续搜索
goto 1;
}
对于在搜索知识库中不存在的路径,即最坏情况,也可以达到采用广度优先算法的搜索效率。找到入口页面后,将交由页面搜索模块进行招聘页面的搜索。
2.2 页面搜索程序
页面搜索程序从招聘入口页面链接开始,搜寻该页面下的所有页面链接,并通过招聘链接识别器过滤出候选的招聘网页链接。
在页面搜索程序的设计策略中,主要有2方面的工作:对页面的解析和高效的搜索策略。虽然已经有基于XML和Web Server的标准,但要将现存的大量页面过渡到这些标准还需要相当长的时间。所以对页面的解析仍需处理大量的不规则格式。例如在链接中就存在着“href= ”、“href =”、“href=" "”以及“href=′ ′”等多种合法的格式,在解析时应该充分考虑各种情况。优良的搜索策略也是必不可少的,存在着像changhong这样巨大的站点,本身有着大量的链接,采用传统的广度优先算法也可以完成搜索任务,但耗时多。具体的算法如下:
//EntranceURL是由入口定位模块给定的入口页面链接
//从EntranceURL开始有限深度遍历站点内的所有网页。返回
//遍历到的网页链接
searchAllLinksBeginWith(EntranceURL)
List open=new LinkedList( );//open表,存放待扩展的节点
List close=new LinkedList( );//close表,存放已遍历的节点
startLink=new Link(startURL,″ ″,0);//初始链接深度为零
open.add(startLink);
while open不为空
first=open.removeFirst( );
addToClose(first);
expandedLinks=expand(first);
removeVisitedLinks(expandedLinks);
addToOpenAtEnd(expandedLinks);
return close;
2.3 招聘链接识别器
招聘链接识别器对链接进行识别,以过滤出候选的招聘网页链接。
此处需要分析的链接包含2个部分:URL和URL对应的文字。例如,对于下面的一段HTML代码片段:
<a href=″http://www.kingsoft.net/business/″class=″cn_12px″>商业合作</a>
| <a href=″http://www.kingsoft.net/c/2003/04/22/71090.shtml″ class=″cn_12px″>诚聘英才</a>
有2个链接:
url1=http://www.kingsoft.net/business/
url2=http://www.kingsoft.net/c/2003/04/22/71090.shtml
这2个链接对应的文字分别为“商业合作”和“诚聘英才”。
很显然,实际需要的是“诚聘英才”所对应的链接,因为“诚聘英才”这4个字往往意味着招聘信息页面。很自然,可以预设一组关键词,如果链接文字中包含其中的某个关键词,便认为该链接对应于招聘信息网页。
但是,仅仅这样还不够。因为有些网页使用图片来导航,通过图片来链接到招聘信息网页。对于图片通常无法识别其具体的含义,也许只能获得URL,而没有对应的文字。而且,关键词词典可能不全面,会遗漏正确的链接。因此,需要引入URL关键词模式。如果URL包含其中的某个关键词,则认为该链接对应于招聘信息网页。
链接识别详细算法如下。
isJobLink(text,url)
//判断一个链接是否为招聘网页链接,text为链接文字,url为
//链接URL
//令textKeywords为包含文字关键词的集合,urlKeywords为包
//含URL关键词的集合
for each word in textKeywords
if (text contain word) return true;
for each word in urlKeywords
if (url contain word) return true;
return false;
2.4 招聘网页识别器
招聘网页识别器根据网页的内容判断其是否属于招聘信息网页。为了避免遗漏,在网页链接识别器中将判断准则放得较宽,所以根据网页链接识别器过滤出来的链接所对应的网页有可能不是招聘信息网页。为此,需要再加入一层限制,即对网页内容进行分析,进一步过滤。招聘网页识别器应用由样本分析模块得到的页面判断知识,从而最终找到招聘页面。
页面判断中引用最广的是基于统计学习的Bayes分类器。但对于本类问题应用Bayes方法却得不到理想结果。中文处理中由于中文分词的难度,使得在选择属性时,不能统计到整个文本所有词语的出现次数。因为出现在非招聘网页(反例)中的单词没有规律,所以如果采用构造词典方法对样本进行统计学习,则所选的词典将是招聘网页(正例)中可能出现的单词。直接采用Bayes方法虽然可以得到一组属性及其在正、反例中出现的统计概率,但将其应用于页面判断时将会得出错误结论:只要页面出现词典中的词,就会被判断为正例。
考虑招聘信息的特点,在判断中并非以某个词出现多少为依据,而应该考虑多个词同时出现的机会,这也是很直观的方法。如一条招聘信息中可能同时出现“xx人员”、“要求”、“工作经验”,但几乎不会同时出现多个“招聘”关键字。
考虑到上述特点,在本模块的实现中,仍然基于关键词,统计所有关键词词典中的词出现的频率的和,如果这个和超过阈值,则认为该网页属于招聘信息网页,否则不是。
3 实验结果及结论
采用上述方法对给定的一定数量的站点进行了搜索的实验,得到了比较理想的效果。由于存在一些不能直接由页面得到链接的站点,或者本身链接的URL不能提供识别而且对应的是图片信息,而开发的程序并没有设计用于识别这类图片的模块,所以在实验统计中只考虑能得到候选链接的情况。通过对候选链接的过滤,最终得到了253个被程序判为招聘的URL地址,其中13个地址属于介绍公司人才观或者包含太多类似招聘页面的词语,可以认为这些属于错判的页面。最终正确率达到了95%,很好地完成了预定任务。
本文对于工作页面的搜索还只是一个初步的尝试,虽然达到了比较好的效果,但仍然存在着许多可以改进的地方。如在一些特殊的情况下,如何获得页面链接,如何改进链接的搜索策略,如何使页面识别器的参数选定最优。接下来的工作将关注搜索策略的改进和更全面的链接解析,以实现低的遗漏率和高正确率。当然对于招聘页面识别只是特定搜索的一个方面,将来的工作是将它做成通用性平台,以满足用户更广泛的要求。
参考文献
1 朱明.数据挖掘.合肥:中国科学技术大学出版社,2002
2 朱明,王胜,周津.基于Web企业竞争对手情报自动搜集平台.微计算机应用,2004;25(1)