
文献标识码: A
文章编号: 0258-7998(2013)03-0040-04
在过去数十年中,摩尔定律下的电路集成密度按照指数率增长,目前的大型芯片已经可以集成数十亿个晶体管。但是,靠提高芯片主频来增加处理器能力的方法会带来日益增长的功耗,致使芯片无法克服散热问题。研究表明,内存中数据的传输和ILP(指令级并行)[1]的复杂控制机制是造成芯片功耗过大的主要原因。而大的片上存储和轻核处理器才是克服功耗过大的有效办法,因此引发了新一轮的并行处理热潮。本设计的处理器采用了特殊的指令集,线程管理器也不同于一般的轻核机器[2]。
1 轻核阵列机
本文设计了一种新型的多线程轻核处理器,该轻核并行处理器是一个阵列机,由多个处理单元簇(cluster)组成,每个簇是由处理单元(PE)组成的一个二维阵列(2D Array),是一种较常见的阵列结构。一个基本簇(base cluster)通常是16个处理单元组成的4×4阵列,如图1所示。其特点是:采用近邻连接的网络拓扑结构;采用双模式的指令集,高效实现并行处理所需的线程间通信;采用专用远程数据传输指令和多播方式及相应的路由器,满足了输出数据的扇出需求和远距离线程间的数据通信。
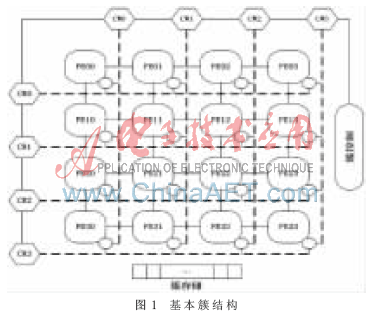
上述特点需要高性能的线程管理机制[3]来提高执行速度和效率。使用软件来进行线程调度无法满足高性能并行计算的要求,因此设计了硬件的管理机制。一个处理单元由一个ALU、一个进程控制器(t-control)、一个路由器(RU)、4个邻接共享存储(MISI)、一个数据存储(D-men)和一个指令存储(I-men)组成,整体结构如图2所示。
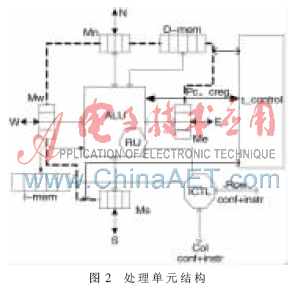
邻居共享存储M[S]分为4个部分:Me(东)、Mw(西)、Ms(南)和Mn(北),每部分用于与相邻处理器通信。在设计中分别为寄存器R28、R29、R30、R31。共享存储器的存取采用阻塞模式(线程间同步),每个共享存储地址都有一位数据有效位。当读取数据时,如果数据无效,则当前线程需要等待;如果数据有效,则读取数据,并将其置为无效。当写入数据时,数据无效则直接写入,数据有效则等待。路由器RU负责将数据传输到远程处理器件,指令控制器(ICTL)模块通过计算把指令写入指令存储(I-men)中,方便处理器对所需指令的读取。
ALU中的指令读取单元含有一个程序计数器(PC)和一个进程地址寄存器(Creg)。每个进程都分配一块数据存储,其基地址可以放在Creg中。T_control完成进程的调度、每个进程自身的状态跳转、每个进程信息的存储,以及事件检测(路由器远程数据传输和相邻的共享存储器中数据的检测)。t_control根据进程表实现一步到位的上下文转换,发送相应的PC和Creg中的当前数值给ALU来调度处理器处理当前进程。
2 进程管理的硬件设计
总体设计中采用8个进程并发执行。进程管理器由一个控制模块(t_manager)、一个就绪队列模块(ready_list)、8个进程的状态转换模块(t_state)、8个进程的寄存器模块(regfile)和一个进程信息表模块(t_table)构成[4],总体设计如图3所示。各模块功能如下:

(1)控制模块(t_manager):首先创建进程,根据每个进程的状态(初始态、就绪态、运行态、阻塞态)创建就绪队列;完成后开始采用轮询的方法控制每个进程的调度[5];最后输出ALU的控制信号。
(2)进程状态转换模块(t_state):主要分为两部分:其一是进程的自身4个状态之间的跳转控制部分;其二是进程阻塞后的检测部分。一般是实现8个或者16个并发进程,图3所示为8个进程的设计图,每个进程需要有自己的t_state模块,图中可以看到8个进程状态控制转换模块。
(3)寄存器模块(regfile):每个进程拥有自己独立的32个寄存器,寄存器R0~R27每个进程自己可以读写,但是邻居处理器不可以读写;寄存器R28~R31是处理器与邻居4个处理器共享的寄存器,本设计的Me(东)、Mw(西)、Ms(南)、Mn(北)4个寄存器分别指的是R28、R29、R30和R31。
(4)进程的相关参数的维护表(t_table):用来记录每个进程的当前状态,并且维护进程阻塞和恢复时的数据。整个控制模块根据这个进程表中的每个进程的当前状态和处理器的忙闲来实现一步到位的上下文转换。
2.1 进程的状态参数表t_table设计
当创建一个进程时,就为进程建立了一个相应的状态参数表,图4所示为一个进程的状态参数表。设计中为8个进程,需要8组如图所示的参数表。状态参数描述如下:

(1)QT:时间片,是指系统给每个进程所分配的执行时间。一旦时间片用完,当前进程就挂起,等待下次的调度。
(2)PC:程序计数器,是指进程的程序在内存或者外存中的物理位置。进程挂起或者阻塞时,首先存储当前程序执行的PC到t_table中,再进行其他操作;进程需要执行时,首先从t_table中读取PC值,再进行程序的读取和其他操作。
(3)STAMP:时间戳。每次从进程开始执行进行计数,如果STAMP==QT,则挂起进程;如果在STAMP!=QT时,进程发生阻塞,则保存当前的STAMP,待下次调度进程时,从保存的STAMP值开始计数并与时间片进行比较。
(4)STATE:状态标志。每个进程都有4个状态,即:IDLE初始状态:00,READY就绪状态:01,RUNNING初始状态:10,WAITING阻塞状态:11。
(5)进程现场保护:AVAIL表示3个算子中是否有数据;MASK表示3个算子是否有用;A0,A1,AD表示进程阻塞时候的3个算子的地址。
(6)ACT:表示进程是否有效。
2.2 控制模块t_manager设计
每个进程都有自身4个状态之间的跳转控制,设计中8个进程采用轮询的调度策略来控制进程的上下文转换,并且产生与处理器之间的接口信号,状态机如图5所示。
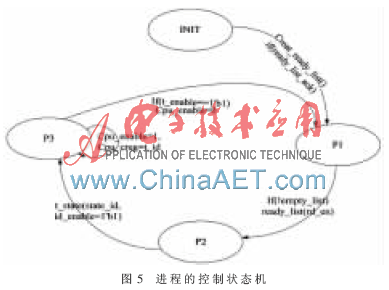
状态跳转解释如下:
(1)INIT:初始状态。首先创建进程和进程的就绪队列,就绪队列完成后跳转到P1状态。
(2)P1:检测就绪队列的空满。如果就绪队列空,则说明没有就绪状态的进程,继续等待就绪队列的产生;如果不空则说明有就绪的进程,采用轮询的调度方法调度进程,即从就绪队列中读取第一个进程号码。
(3)P2:发送进程id号码到进程状态控制模块t_state,并且发送进程处理信号id_enable为高电平给进程状态控制模块t_state,跳转到P3状态。
(4)P3:发送信号cpu_enable(高电平)、cpu_creg(进程id号码)、pc(进程的程序地址)给处理器,等待处理器的处理。一旦信号t_enbale为高电平,表示当前进程挂起或者执行完成了,则跳转到P1状态,cpu_enable置低。
2.3 进程状态转换模块t_state设计
进程状态转换模块的设计分为两部分介绍:一是进程自身4个状态之间的跳转控制部分的详细设计;二是每个进程阻塞后的检测部分的详细设计。下面主要介绍单个进程的状态控制。
每个进程都有4个状态,跳转如图6所示。各状态说明如下:

(1)INIT:初始状态。检测进程的PCB表的act信息,一旦为高(表示进程是可用的),则跳转到下一个状态READY。
(2)READY:就绪状态,表示进程已经具备了运行条件,但是处理器不一定是空闲的,如果不空闲,则暂时不能使用,需等待分配处理器。即检测进程启动信号id_enable,一旦为高(表示处理器空闲,进程可以执行),则跳转到RUNNING状态。
(3)RUNNING:运行状态。首先读取t_table中对应进程号的QT(时间片)、PC(进程的程序的计数器)和STAMP(时间戳);处理器开始执行该进程的程序后,时间戳与时间片相等了,表示该进程的时间片结束了,则跳转到READY状态,并且保护现场,把当前的进程号写入就绪队列中,等待下次的调度;当处理过程中发生了阻塞,则跳转到WAIT状态,把当前的PC(进程的程序的计数器)、STAMP(时间戳)、MASK(3个算子中有用的算子标志)、AVAIL(3个算子中有数据的标志)、A0,A1,AD(3个算子的地址)写入t_table中,保护现场;当进程的程序处理完时,act置低,跳转到INIT状态,不再被调度。
(4)WAIT:阻塞状态,即进程在运行过程中,因为等待某一事件(如等待一个输入/输出操作完成)而暂时不能运行的状态。这种状态下,发送t_enable高电平到进程控制模块,同时启动监测模块进行所需数据的监测,如果t_flag为高电平,则表示监测信号监测到了相应的数据,此时进程恢复READY状态,并且跳转到READY状态,等待下一次进程的启动。
3 验证和分析
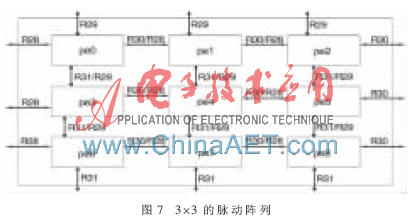
电路设计采用Verilog硬件描述语言,在Xinlinx公司的ISE环境下完成功能仿真和综合。在阵列机的基础上,采用指令集编写简单的算法完成了简单功能测试。算法如3×3矩阵的加减法、多个数的最大公约数与最小公倍数的求解和奇偶算法。图7所示是一个简单的3×3阵列机,采用一个处理器和一个进程控制器组成一个pe,图中的寄存器是相邻处理器之间的共享寄存器。
3.1 轻核阵列机的功能测试
测试激励为:pe0、pe1、pe2各自包括3个进程,3个进程分别执行不同的3×3矩阵加法。图7所示的pe之间的寄存器(即共享寄存器)中,R30/R28是pe与左右邻之间的共享寄存器,R31/R29是pe与上下邻之间的共享寄存器。
根据测试激励,pe0会发生阻塞,pe1和pe3进程都是顺序执行。pe0的仿真结果图如8所示,分析如下:
(1)首先执行0号进程。从图中cpu_creg为000(0号进程)的信号可以看出,当执行完成以后没有发现阻塞,进程0顺利执行完成,信号t_over为高。

(2)然后根据调度算法调度1号进程(cpu_creg为001)。信号cpu_flag为标志信号,其为1表示寄存器R8或者R31没有数据,此时发生阻塞,则挂起1号进程,同时启用监测模块对1号进程没有数据的寄存器R31进行监测。
(3)在监测的同时根据调度算法调度2号进程(cpu_
creg为010)。若2号进程也发生了阻塞(cpu_flag为1),则挂起2号进程,同时进行2号进程所需要的数据的监测;在2号进程的执行过程中1号进程就绪,这时2号进程一旦挂起则调度1号进程(cpu_creg为001)继续执行,直到1号进程执行完成(t_over为1);重复以上操作,处理完所有的进程。
3.2 奇偶排序
基于奇偶原理和归并—拆分模式[6-7],在线性阵列上实现并行排序,步骤如下:
(1)将6个数据分别存储到6个pe的寄存器R0中。
(2)开始进行第一次偶排序,此时pe0、pe2、pe4分别读取R30(CPU与右邻的共享寄存器)的数据,而pe1、pe3、pe5把数据从寄存器R0移到R28中,这样3个pe并发地执行第一次偶排序。
(3)开始进行第一次奇排序,此时pe1、pe3通过R30读取右邻的pe2、pe4中的数据,pe2、pe4在上次的偶排序时已经把数据存放到自身寄存器R28中,这样2个pe并发地执行第一次奇排序,pe0和pe5等待下次的偶排序。
(4)重复步骤(2)和步骤(3),最多执行6/2=3次即可得到最后的结果。
多线程轻核阵列机是一个新提出的概念,目前所采用的进程管理器都是由软件实现,而对于轻核阵列机中的进程调度采用软件的方式很难实现高效的上下文转换,故本文采用硬件实现进程管理,对电路进行了模块划分和详细设计,最后在Xilinx的ISE环境中完成了轻核阵列机的功能仿真和综合。硬件设计使得进程的上下文转换和监测不占用处理器的处理时间,简化了进程间的通信,从而明显地提高了执行效率。
参考文献
[1] RAU B R,FISHER J A.Instruction-level parallel processing:history,over view and perspective[J].Journal of Supercomputing,1993,7(1):24-31.
[2] 李涛.一种图形处理器的轻核阵列机结构[J].西安邮电大学学报,2012,17(3):42-46.
[3] MAROWKA A,GAN R.Back to thin-core massively parallel processors[J].IEEE Computer,2011,44(12):49-54.
[4] STALLINGS W.Operating systems Internals and design principles[M].Seven Edition,Prentice Hall,2012:158-171.
[5] Liu Chunglang,LAYLAND J W.Scheduling algorithms for multiprogramming in a hard-real-time environment[J].Journal of the ACM,1973,20(1):46-61.
[6] 祁金才,张锦雄,黄毅,等.线性阵列上的奇偶归拆排序并行算法的MPI实现[J].广西大学学报(自然科学版),2005(S2):88-89.
[7] 官东.基于并行计算机的奇偶交换排序[J].荆门职业技术学院学报,1999,14(6):28-29.