
摘 要:提出了一种改进互信息的译文选择方法,认为词语的译文的选择不是孤立进行的,上下文对译文的选择有着重要的意义,通过对已有的互信息公式加入翻译模型特征进行改进,结合翻译模型与互信息来选择最佳译文,经过BLEU(BiLingual Evaluation Understudy)作为机器评价准则的实验结果表明,该方法优于传统的互信息词语译文选择的方法。
关键词:互信息;译文选择;翻译模型;译文选择模型
译文选择是指根据从语料库中学习翻译知识,为源语言词选择对应的目标语言词。词译文选择的好坏决定了机器翻译系统的质量。Gale等人[1]应用基于大型英法对齐语料库的统计方法,对6个常见的歧义词的消歧正确率在82%~86%。刘小虎建立多上下文特征的词义消歧统计模型,对歧义词“interest”消歧测试的正确率达到80%[2];而通过在英汉机译系统的译文选择中引入改进的ID3机器学习方法[3],歧义词“interest”消歧测试的正确率可达到91%,荀恩东[4]在译文选择中使用以消歧矩阵为计算背景的贪心算法。Dagan[5]等人提出利用目标语同现统计消除源语言歧义的思想。哈尔滨工业大学BT863-2英汉机译系统继承Dagan的思想,译文选择的正确率为75%。术语相关性计算的研究比较典型,有EMMI weighting measure[6]、Term Similarity[7-9],本文方法与参考文献[10]中提出的查询翻译中用到的方法有些相似。
1 译文选择模型
Ballesteros和Croft[8]认为对语料库进行共现频率的统计有助于消除翻译的歧义问题。他们假定正确的翻译更可能在同一个目标句子中共现,否则相反。参考文献[7-9]也使用相类似的方法选择最佳的词语翻译。
正是因为各个词之间的关系不是相互独立的,本文提出词语相关性和翻译概率相结合的方法来选择相应的词语翻译,而不是逐词孤立地翻译。当翻译一个词语时,其他待翻译词的候选翻译会成为它的上下文信息,这是本文进行翻译选择的原则。给定一个待翻译的英文词语的集合,通过贪心算法和下文中的公式(5)找到每个词的正确译文。
例如,输入NP(Noun Phrase):IC card intelligent door lock。
在本文的双语词典中,“intelligent”对应的翻译候选有:(1) 智能国;(2) 智力。依次类推本例中的目标集合T为{“IC”,“卡”,“门”,“通道”,“锁”,“锁头”}。目标集合的获得是通过在双语词典中查找每个源语言词对应的汉语翻译候选组成的集合。通过公式(1)~(3)[11]计算,找到最可能的目标翻译,上例计算得到的翻译结果为“IC 卡 智能 门 锁”。
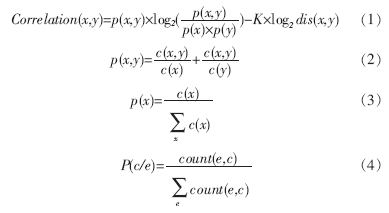

具体算法如图1所示。

2 实验结果及分析
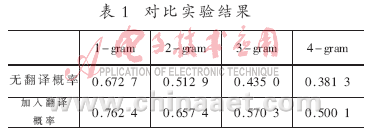
本文将翻译概率加入到公式(1)中,结合翻译概率与互信息来进行译文的选择,对比实验结果可知,翻译概率对翻译结果有较大的提高。
为了充分证明该结果,从英汉术语实例库中,随机挑选500个实例进行对比测试,采用NIST发布的最新版本mteval-v11b.pl作为自动翻译结果的评测工具,实验结果的曲线图如图2所示。

从表1中可以看出,加入翻译概率后,从1-gram到4-gram的BLEU值都有所提高。为了更加清楚地显示其对比效果,可以参见图2。
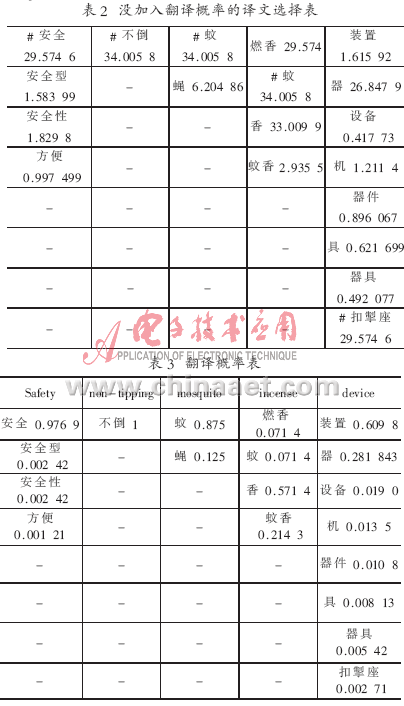
举一具体实例来说明上面原因。例如:输入NP:Safety non-tipping mosquito incense device,在不加入翻译概率时,只通过公式(1)计算得出翻译结果为:“安全不倒蚊蚊扣掣座”。
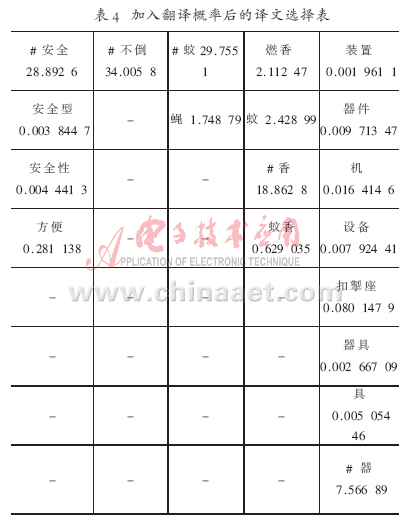
分析其原因,从表2可知,在没有加入翻译概率之前,通过公式(2)计算,“incense”选择了“蚊”这个译文,因为“蚊”的值最大,如表3所示。在加入翻译概率改进之后,通过公式(5)计算,结果如表2所示,由于其翻译概率很小,因此就会选择到更合适的译文“香”。(“#”表示选择的译文)根据表4,正确的译文为:“安全 不倒 蚊 香 器”。
译文选择的好坏是机器翻译质量提高的关键。本文提出的改进互信息的译文选择方法,其中对互信息的理论作了简单介绍,对译文选择的相关研究也进行了简单描述。通过对比实验分析证明了该方法在已有的互信息方法上加入翻译模型特征后,翻译效果得到显著地提高,BLEU值提高了0.1左右。
参考文献
[1] WILLIAM G, KENNETH C, DAVID Y. Using bilingual materials to develop word sense disambiguation methods[C]. The 4th Int’l Conf on Theoretical and Methodological Issues in Machine Translation, Montreal, Canada, 1992.
[2] LIU Xiao Hu, Li Sheng , Zhao Tie Jun . Statistical model selection for word sense disambiguation(in Chinse)[J]. Communications of Chinese and Oriental Languages Information Processing Society, 1997, 7(2): 69-75.
[3] 刘小虎. 英汉机器翻译中词义消歧的研究[M]. 哈尔滨:哈尔滨工业大学, 1997.
[4] 荀恩东, 李生, 赵铁军. 基于汉语二元同现的统计词义消歧方法研究[J].高技术通讯, 1998, 10(8): 21-25.
[5] DAGAN, LILLIAN L, FERNANDO P. Similarity-based models of cooccurrence probabilities[J]. Machine Learning, Special Issue on Natural Language Learning, 1999, 34(1-3): 43-69.
[6] RIJSBERGEN V . Information retrieval[J]. 2nd ed. Butterworths, London, 1979.
[7] ADRIANI M. Using statistical term similarity for sense disambiguation in cross-language information Retrieval[C]. Information Retrieval, 2000,2: 69-80.
[8] BALLESTEROS L, CROFT W B Resolving ambiguity for cross-language retrieval[C]. In Proceedings of the 21st International Conference on Research and Development in Information Retrieval,1998.
[9] BALLESTEROS L , CROFT W B. Phrasal translation and query expansion techniques for cross-language information retrieval[C]. In: Proceedings of the 20th International Conference on Research and Development in Information Retrieval, 1997: 84-91.
[10] GAO J F , NIE J Y. A study of statistical models for query translation:finding a good unit of translation[C]. In SIGIR, 2006.
[11] GAO Jian Feng, NIE Jian Yun, ZHANG Jian, et al. Improving query translation for cross-language information retrieval using statistical models[C]. In SIGIR’01, NewOrleans, Louisiana, 2001: 96-104.