
DSP接口效率的分析与提高
2008-09-03
作者:胡荣强 胡 鹏
摘 要: 分析了导致DSP系统接口效率低下的几种情况,重点叙述了相应的提高效率的设计方法,并提供了电路图和源程序。
关键词: DSP 接口电路 CAN控制器
近几年来,数字信号处理器(DSP)得到了广泛的应用。由于DSP采用程序空间和数据空间分离的哈佛结构,对程序和数据并行操作,使之成倍地提高了处理速度;再加上流水线技术,使得DSP的指令周期多为10ns级。而与之配套的外围器件却没有像DSP那样迅猛地发展。首先,DSP与外围器件之间的速度差异日益显著,大部分外围器件的读写周期" title="读写周期">读写周期在50ns以上,即使是最快的静态RAM,其读写周期亦为8ns左右,也只能与50MHz以下的DSP直接接口;其次,一些领域的器件在设计时并没有考虑与DSP接口,以至于不能直接接入DSP总线,如CAN总线控制器SJA1000采用地址总线与数据总线分时复用" title="复用">复用的总线接口。这使得DSP与许多外部器件难以接口,特别是在与多个外部器件接口或者与总线不兼容的外部器件接口时,常常会出现因接口处理不当而导致接口效率低下的情况。当DSP对外部器件的操作频率很高时,接口效率的高低将对系统的运行速度产生不可忽略的影响。
1 多个外设的情况
当DSP与低速器件接口时,可以通过设置DSP片内的等待状态产生控制寄存器(WSGR),在相应的程序空间、数据空间或I/O空间产生1~7个等待周期,以使DSP的访问速度能和低速器件相匹配。当在同一空间内既有低速器件又有高速器件" title="高速器件">高速器件时,通常WSGR的延时值被设置成与速度最慢的器件相一致,以保证DSP对所有的器件都能进行正确的访问。若对高速器件的操作很频繁,则这种对整个空间的延时将极不合理地降低系统速度。例如,有些系统在数据空间同时扩展有RAM和ROM。而ROM的速度一般远远低于RAM,其访问周期一般为100~200ns,即使DSP和RAM的访问速度均可达到25ns,但对整个数据空间进行延时后,DSP也只能以ROM的访问速度(100~200ns)对RAM进行访问。
在这种情况下,首先应考虑使用软件方法提高效率。其方法是在默认的情况下将WSGR设置成与高速器件一致,当要访问低速器件时再修改WSGR的值。DSP常常对外部器件进行连续操作,在这种情况下,软件方法还是比较有效的。但最大问题在于增加了软件负担和不稳定因素。
显然,效率最高的情况是,既不需要修改WSGR,DSP又能以外部器件本身的速度对它们进行访问。事实上,只要能够产生适当的信号控制DSP的READY端,就可以达到这个目的。DSP在开始一个外部总线的操作后,会在每一个CLKOUT信号(DSP的时钟输出)的上升沿时刻对READY端进行查询,若READY为低,则保持总线的状态不变,然后在下一个CLKOUT上升沿时刻再次查询,直至查询到READY为高时结束本次总线访问。
下面的设计实例中介绍的硬件等待电路(见图1)能够实现这个功能。它针对不同的外部器件产生相应的等待信号送到DSP的READY端,实现硬等待。其核心器件采用了广泛应用的通用逻辑阵列(GAL),GAL的引脚定义与图1相对应。使用GAL器件使硬件设计变得简单而灵活,可以完成比较复杂的逻辑关系。
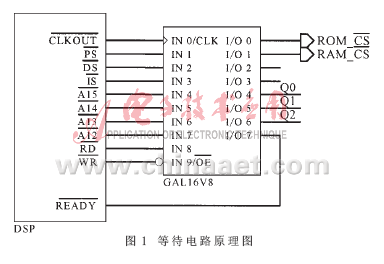
例如,频率为50MHz的DSP在数据空间外扩有RAM和ROM各一片,访问周期分别为70ns和150ns,地址空间分别为0x8000~0x8fff和0x9000~0x9fff。由DSP的主频可知,对RAM和ROM的访问各需插入3个和7个等待周期。下面给出GAL源文件的关键部分(它们使用汇编程序FM的格式编写):
Q0:=/Q0*/RD+/Q0*/WR
Q1:=/Q0*Q1*/RD+Q0*/Q1*/RD+/Q0*Q1*/WR+Q0*/Q1*/WR
Q2:=/Q1*Q2*/RD+/Q0*Q1*Q2*/RD+Q0*Q1*/Q2*/RD+/Q1*Q2*/WR+/Q0*Q1*Q2*/WR+Q0*Q1*/Q2*/WR
;构成一个三位的二进制计数器
;Q2为最高位、Q0为最低位
;对读信号或写信号的宽度进行计数
GAL_READY.OE=VCC
/GAL_READY=/DS*A15*/A14*/A13*/A12*/Q1
+/DS*A15*/A14*/A13*/A12*Q1*/Q0
;为RAM的访问插入3个周期
+/DS*A15*/A14*/A13*A12*/Q0
+/DS*A15*/A14*/A13*A12*/Q1
+/DS*A15*/A14*/A13*A12*/Q2
;为ROM的访问插入7个周期
图2是一个与写时序对应的时序图,其中在下三角符号标出的时刻,DSP对READY端进行查询。

这种方法能够充分使用硬件的速度,并且对软件是透明的,不会增加编程人员的负担。
2 总线不兼容的情况
有一类芯片的总线接口是分时复用的,如CAN总线控制器SJA1000。SJA1000有8位的数据和地址复用的总线,可以和多种MCU直接相连。一次总线操作开始时,总线先传递此次操作访问的地址,在ALE信号将地址锁存" title="锁存">锁存后,再进行数据读写。而DSP的数据总线和地址总线被并行地引出,这种并行结构比分时复用的串行结构先进,有着高一倍的带宽。但DSP被设计时并没有考虑过会在芯片外将并行的总线再串行化,也就没有设计相应的辅助信号来完成这种转换。这使得完全使用硬件方法进行串行转换比较困难。
此类问题通常使用软件和硬件配合解决,并不真正地靠硬件进行转换,而是把一次总线操作分解成两步。先把此次操作的目标地址作为数据送到总线上,同时通过硬件产生一个锁存信号将其锁存。然后再进行读写操作" title="读写操作">读写操作,读写操作的目标地址就是上一步被锁存的地址。
使用这种办法,硬件和软件都不需要进行复杂的变换。唯一的缺点是指令的效率变低了。由于SJA1000的读写周期一般是DSP的指令周期的几倍,一次访问被分解成两次后多消耗的时间不能忽略。还有一个更重要的影响是,这种转换方法在寻址时无法使用DSP的并行寻址功能,必须使用另外的变量独立运算。在多数的CAN总线应用中,这种处理方法不会对系统的整体性能产生太大的影响。但在有的系统中,这种低效是不可容忍的,如由DSP和SJA1000组成的CAN总线网关,它含有多个SJA1000芯片,并且在SJA1000之间需要经常进行数据块的搬移。对于次数频繁并且寻址有规律的操作,利用DSP的并行寻址功能将极大地提高程序的效率。以下程序段可在两个不同网段的SJA1000之间完成一帧消息搬移功能(它在每次操作的同时对下次操作的地址进行并行寻址):
Lar ar0,mlength ;取消息的长度
Lar ar1,#SJA1_A ;一个SJA1000中接收邮箱的首地址
Lar ar2,#SJA2_S ;另一个SJA1000中发送邮箱的首地址
Mar *,ar0
Mar *-,ar1
Loop: ;复制一帧消息
Lacl *+,ar2
Sacl *+,ar0
Banz loop,*-,ar1
如果按上述方法改写这段程序,不仅对SJA1000的操作时间要增加一倍,而且每次操作前都要对地址进行运算,使得完成同样功能的程序运行时间要增加到原来的3~4倍。
这时,只有使用纯硬件的解决方法才能获得理想的效果。设计的关键是生成合适的锁存信号ALE,使它能够满足SJA1000的时序要求。通过研究DSP控制信号的时序可以发现,从地址建立到读写控制信号有效大约要经历二分之一个CPU时钟的时间,而SJA1000的ALE信号要求的最小宽度为8ns,因此对于主频在50MHz(CPU时钟为20ns)以下的DSP,可以利用这二分之一个CPU时钟的时间间隙生成ALE信号。图3给出了含两片SJA1000的接口电路图。除了片选信号外,这两片SJA1000的总线和其它控制信号都连在一起。

假设SJA1000的片选地址为0X8xxx和0X9xxx,各引脚定义与图中对应,则GAL中的逻辑关系如下:
/ADDR_G=DSP_RD*DSP_WR*RD*WR
/DATA_G=/DSP_DS*DSP_A15*/DSP_A14*/DSP_A13*ADDR_G
/WR=/DSP_WR*/ALE
/RD=/DSP_RD*/ALE
ALE=/DSP_DS*DSP_A15*/DSP_A14*/DSP_A13 *DSP_RD*DSP_WR
/CS1=/DSP_DS*DSP_A15*/DSP_A14*/DSP_A13*/DSP_A12*ADDR_G
/CS2=/DSP_DS*DSP_A15*/DSP_A14*/DSP_A13*DSP_A12*ADDR_G
对其中一片进行读写操作,则时序关系如图4所示。

其中,twr、tww分别为DSP读、写时的ALE信号宽度,它们都接近1/2个CLKOUT的周期。t为ALE的下降沿到RD、WR有效的时间,它由GAL翻转的延时产生,为10ns以上(注:本图中DSP的时序来自TMS320C24xxA系列,不同系列的DSP产品之间时序可能有细微的差别)。
对于主频高于50MHz的DSP,应当使用有更高工作频率的可编程逻辑器件,并将前面介绍的计数器引入可编程逻辑器件内,来产生满足时序要求的锁存信号。
本文介绍的两种高效率的DSP接口的设计方法,去掉了在DSP访问外设时任何不必要的时间消耗。当然,效率的提高是以增加硬件的复杂度为代价的,在能够满足设计要求的前提下,设计者应该选择简单的设计方案。而对于频繁进行外设访问的高性能系统,本文提供了理想的接口方案。
参考文献
1 张雄伟, 曹铁勇.DSP芯片的原理与开发应用, 北京: 电子工业出版社,2000
2 TMS320LF24xxA Datasheet, Texas Instruments,2002
3 SJA1000 Product Specification. Philips Semiconductors,2000