
摘 要: 根据图聚类节点的密度变化确定核心节点,构成连通子图并确定邮件网络社区划分的个数及初始社区中心点,通过社区中心动态调整的方法将非核心节点划分至所属社区。实验证明了该邮件网络社区划分的有效性和可行性。
关键词: 图聚类;邮件社区划分;动态中心
随着互联网的发展,网络成为工作和生活中相互联系的重要工具,与此同时,网络社区[1]也应运而生。网络社区是指基于电脑网络的虚拟社会关系网络的载体,在这种网络中,相同类型的节点之间存在较多的连接,而不同类型节点之间的连接则相对较少。网络社区通常满足六度分割理论及150法则[2]等特征,通常是现实社区的近似。因此对网络社区的发现,对了解现实社会中的社会关系网络有着特别重要的意义。
邮件社区作为一种网络社区,同样与现实的社会关系网络同构,满足小世界网络模型[3],由于电子邮件本身的优势[4],有利于发现社会关系网络的动态特性。目前有关网络社区发现的研究较多,具有代表性的方法有Girvan和Newman提出的基于去边的G-N算法[5]、Aaron和Newman的层次聚类的算法以及基于三角环的Radicchi方法[5]等。但这些算法时间复杂度高,不易于处理大规模的网络。
本文从图论的角度出发,首先采用基于贪心的图形聚类算法,通过计算节点序列密度变化确定社区划分的个数及每个社区的核心代表节点,然后以这些核心节点为中心,采用基于节点相似度的动态中心调整算法将节点划分到其所属的社区中,从而完成对邮件社区的划分。
1 基本概念
邮件网络是社会网络的一种,可以采取社会网络的相关方法对邮件网络进行社区划分。为了便于算法的描述,首先对文中使用的社会网络图及相关概念进行数学描述和说明。



2 挖掘社会关系网络
基于电子邮件的社会网络分析可以分为两个步骤:(1)利用邮件日志信息构建有向有权社会网络,网络图中顶点表示电子邮件的收件人或发件人,连线表示两节点之间存在收发联系;(2)使用改进的算法来挖掘隐含在此网络图中的社会关系,即对网络图进行社区挖掘。
2.1 构建社会关系网络
根据电子邮件地址直接构造一个有向有权图,图中顶点表示联系人,连线表示顶点之间联系的收发频率。为了减少噪声节点对整个网络的影响,在构图之前,通过设定阈值,选取收发邮件大于该阈值的节点,然后构造社会关系网络图并通过邻接表和逆邻接表进行存储,从而有利于节省空间并方便节点的出入度计算(在本文中,选取indeg(vi)≥3以及outdeg(vi)≥3的节点,即阈值为3)。
2.2 邮件社区划分
邮件社区划分的基本思想:从图的划分以及聚类的角度出发,分别从节点的密度变化和节点对之间的相似度进行考察,并采取社区中心动态调整的技术,主要分为以下步骤:
(1)通过检测网络图中节点的密度变化,确定聚类个数及聚类核心;
(2)节点的划分和各社区中心的调整。
2.2.1 聚类个数及聚类核心求解算法
假设每一个邮件网络图中都存在一个被称为“聚类核心点”的高密集区域,这些聚类核心点被密度稀疏的点所包围。则聚类核心中的节点被称为核心节点,核心节点的集合为核心节点集,而包含这些核心节点的子图叫做核心子图。
根据式(1)、(2)求解出每个节点的局部密度以及集合H中密度最弱的节点集合。因此,通过分析最小密度值D(H)的变化,可以近似地求出所有的核心节点集。即如果密度最小的节点存在于稀疏区域,则当删除该节点时D值会增大,那么下一个被删除的节点必将存在于密度更高的节点区域内。如果某个节点的删除引起D值的急剧下降,则该节点很有可能存在于密度较高的区域,也有可能因为节点的删除导致了周围其他节点的密度下降。算法(1)给出了计算密度序列变化的执行步骤。

找出了所有满足条件的核心节点集,可以通过多种方法将这些核心节点集划分为核心子图并最终确定聚类个数及聚类核心点。由于邮件网络图为稀疏图,由核心节点所构成的连通子图称为核心子图,核心子图个数为聚类个数,则核心子图中的节点就为聚类核心点。
2.2.2 社区划分算法
算法(2)描述了邮件网络社区划分步骤,ENCD(Email Network Community Detecting)邮件网络社区划分算法。

3 社区划分实验
本文所选实验数据集为enron邮件数据集以及苏州大学2009年2月至5月之间的邮件日志内容。其中在http://www-2.cs.cmu.edu/~enron/可下载到enron数据集,它包括预处理后的151个节点以及252 759条边。苏州大学邮件日志内容有183 925个节点以及391 347条边,内容含校内邮箱间的邮件收发信息以及相关的校外邮箱的邮件收发信息。
在本实验中,由于考虑到苏州大学邮箱用户的隐私问题,对邮箱地址进行了MD5转换,并且对于每个邮箱mailbox,均由一个邮箱编码mailboxlD唯一标识。
本实验的实验环境为2.80 GHz Pentium CPU,1GB内存,80 GB硬盘,操作系统为Microsoft Windows XP,程序开发平台为Myeclipse。社区划分结果的每一项由两个字段组成:邮箱编码mailboxlD和社区标号CommunitylD。
图1是enron数据集构成的社会网络图,图2显示了本文参数对enron数据集社区划分最终结果的影响。由图可以看出,不同的?鄣值对确定社区划分数量影响不大。

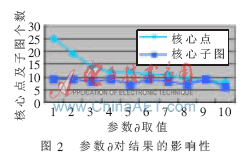
表1显示了使用本文算法与G-N算法在enron以及苏州大学邮件数据集上的结果比较,其中 取值0.26。modularity[5]为算法的评价指标之一,通常为(0,1)的小数,且值越大说明社区划分的质量越高。图3描述了本文算法与G-N算法在enron数据集上社区密度的对比。图4是在enron数据集上社区有效直径的对比图。
取值0.26。modularity[5]为算法的评价指标之一,通常为(0,1)的小数,且值越大说明社区划分的质量越高。图3描述了本文算法与G-N算法在enron数据集上社区密度的对比。图4是在enron数据集上社区有效直径的对比图。
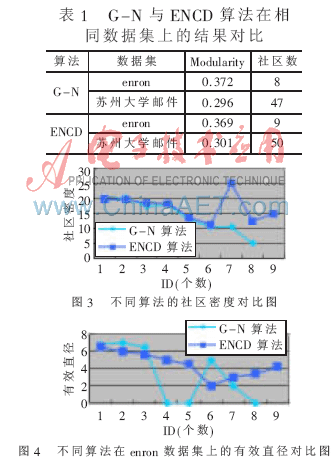
由表1可以看出,本文提出算法在社区划分个数方面与G-N相当。但是,G-N算法用于enron数据集所发现的社区结果中,有两个社区中的节点只有1个,还有一个社区的节点个数为2个。这显然与社区划分步骤(1)矛盾,而本文提出的算法所求出的每个社区中节点个数则相对比较平均。图3中G-N算法得出的社区密度最小为5,最大约为20;而本文算法得出的最小值约为10,并且最大峰值为25。可见,本文算法在enron上划分的社区内部联系更加紧密。图4说明了G-N算法与ENCD算法得出的社区有效直径均相当,因此本文算法用于网络社区划分是可行的。
4 分析与评估
邮件社区的划分本质上是稀疏图聚类的问题,而此类划分又是NP完全问题[6]。Girvan和Newman提出的基于去边的G-N算法,在图划分上得取得了很好的效果,但是时间复杂度较高,为O(E2V),其中,E为网络图中边数、V为节点数。因此,不利于大规模的网络社区发现。而本文算法(1)由于使用了邻接表及逆邻接表结构,所以,时间复杂度为O(|E|+|V|log|V|)+O(|V|)+O(|Ec|),其中Ec为核心图中的连接边数。算法(2)时间复杂度为O(E)。所以最坏的间复杂度为O(|E|+|V|log|V|)。苏州大学邮件数据集上测试的结果表明,本文方法执行效率要优于G-N算法。
本文提出了一种新型的基于核心图聚类算法的邮件网络社区划分,首先通过计算节点的密度变化找出满足条件的核心节点,然后将这些核心节点集划分为核心图,最后通过节点相似度将未划分的节点划分到最相似的子图中。在enron以及苏州大学邮件数据集上的结果表明,本文算法在社区划分的质量上与G-N算法相当,但是执行效率要高于G-N。此外,本文算法还支持一个节点属于多个社区的情况,而这种情况在现实生活中是极为常见的。
参考文献
[1] ZHANG Y C, YU Xj, HOU L Y. Web communities: Analysis and construction[M]. Berlin: Springer, 2005.
[2] STROGATZ S H. Exploring complex networks[J]. Nature, 2001(410):268-276.
[3] 陈绍宇,宋佳兴,刘卫东,等.关系网络:一种基于小世界模型的社会关系网络[J].计算机应用研究,2006,23(5):194-197.
[4] ALSTYNE M V, ZHANG J. EmailNet: A system for automatically mining social networks from organizational email communication[C]. In NAACSOS2003, 2003.
[5] MARK E J, NEWMAN M. Finding and evaluating community structure in networks[M]. Physical Review E,69. 026113, 2004.
[6] GIRVAN M, NEWMAN M. Community structure in social and biological networks[J]. Proc. Natl. Acad. Sci. USA 2002(99):8271-8276.